
Raise your team's cost IQ: RAM, AI supply chain inflation, new tradeoffs for local vs cloud

What do you do when a new innovation increases costs??
Dire Straits
At time of writing/recording, the Iran conflict is about to enter its 7th day, as capitals and economic hubs worldwide are watching for indications of how long this conflict will last. The longer it goes on, the more we risk a global inflationary shock. The US average price for a gallon of gas is up 27 cents this week.
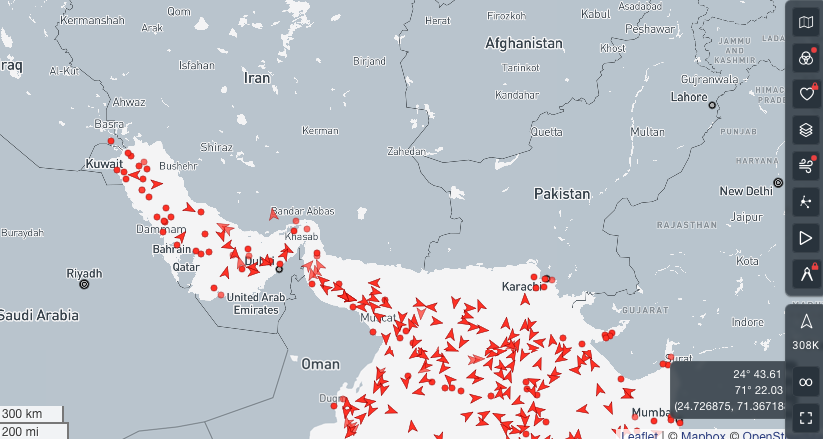
This comes at a particularly bad time for the already volatile economics of compute. By disrupting the energy supply chain, the conflict is directly inflating the cost of energy—the primary input for AI compute. This will add to the feedback loop of rising operational costs and market volatility across all digitized industries.
That's why this week we need to dig into the crucial intersection where technology, economics and skillsets come together. We want to be grounded in:
- The economic realities now impacting tech choices we make and
- The specific skills and actions teams can use to reposition for best possible outcomes.
What seems unique about this time period
For the tech history that I have witnessed dating back to the early 90's - all the waves of innovation always tended to reduce costs and raise productivity in undeniable ways.
What seems unique about where we are today, is that the current wave of technology innovation is actually increasing costs, and not creating consistently meaningful and observable productivity gains.
This is not to say there will be no productivity gains or benefits. Or that costs structures will never streamline. But it does require us to get smarter and more selective about how we apply these new technologies. Smarter and more selective won't come from bringing the right speaker to your next board meeting or investment committee: it will come from empowering your team to experiment and learn how to match your company's compute workloads to the most cost effective form of compute.
That's what we'll dig into today. Let's start by familiarizing ourselves with the current economics of compute.
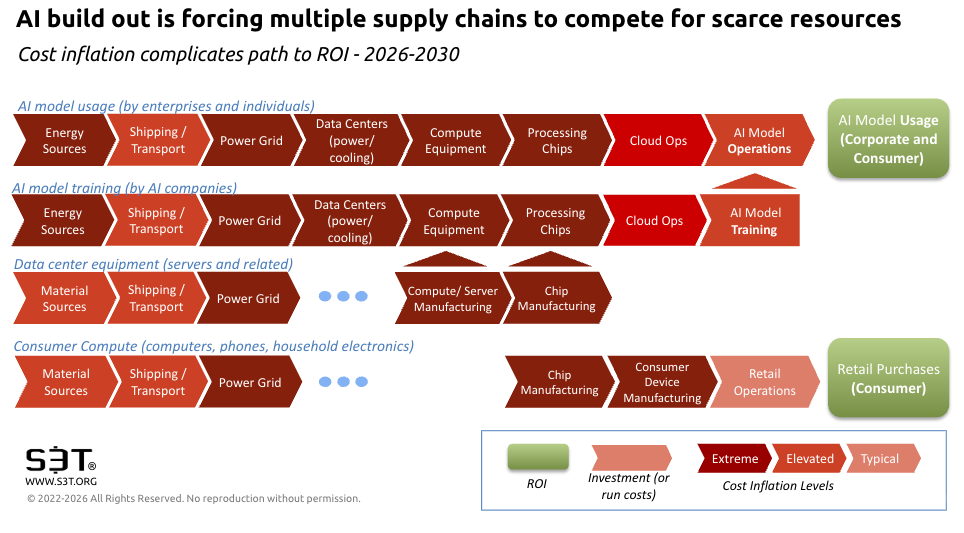
The inflationary impact of hyperscalers
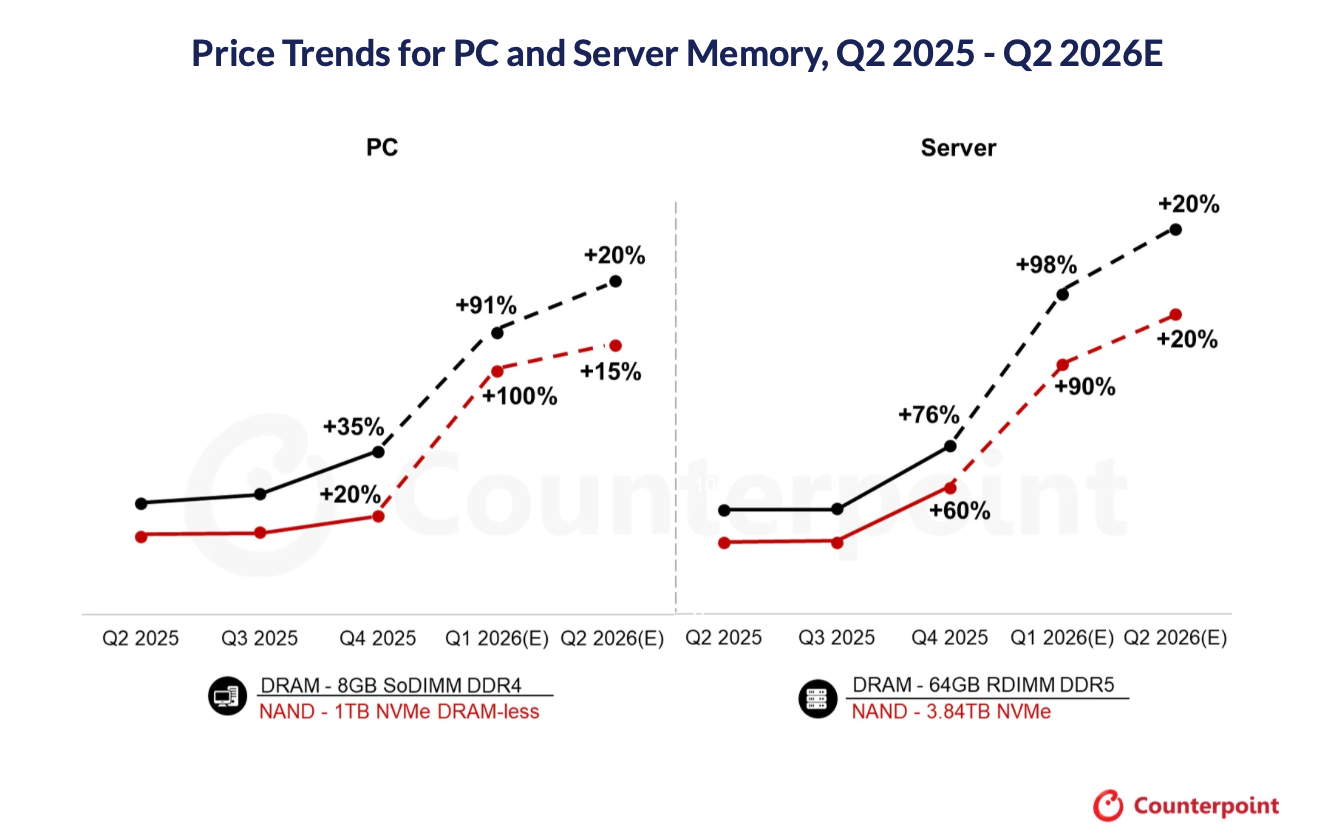
RAM prices are up 90% so far in 2026 as chip manufacturers (Samsung, SK Hynix, and Micron) redirect massive amounts of their chip production away from consumer products to High Bandwidth Memory (HBM) to satisfy demand for AI accelerators like Nvidia’s H100 and B200. This comes on top of sharp price increases that already occurred in 2025.
“Just to give you an idea, a single AI server can use as much advanced memory as a dozen or even hundreds of traditional laptops” observes Matteo Rinaldi who sees this as a more structural long lasting issue than the temporary supply chain shocks during Covid.
Implications:
- Digital products inflation: rising prices for consumer products - phones, computers, consoles - as OpenAI, Microsoft, Google and others grab as much processing power and chip supply as they can.
- Planning dilemmas for teams. If you bought hardware prior to the RAM cost spike, find a way to use it.
Connecting the economic dots
The massive investment poured into AI big tech - that pushed stocks to new highs amid otherwise flat to negative conditions - has to get paid back ...somehow. As shown in the AI supply chain diagram above, this is going to get complicated.
Tech titans are betting they can create ROI by bringing enterprises and consumers into their controlled cloud environments and charging for usage.
But businesses are starting to learn what this means for their bottom line. So far the cost savings from enterprise AI have not kept up with the rising costs of using enterprise AI - especially agentic AI.
This Deloitte paper notes that proactive organizations are starting to rethink compute - specifically how they match workloads to processing power:
"On-prem compute may be more cost effective than cloud for consistent, high-volume workloads...when cloud costs begin to exceed 60% to 70% of the total cost of acquiring equivalent on-premises systems, making capital investment more attractive than operational expenses for predictable AI workloads."
As companies become more cost conscious, and the realization of limited ROI takes hold, there will likely be a pricing strategy competition (in the AI value chain) as AI players scramble to shore up their margins and - hopefully - pay back their investors. This will not be fun. It will likely bear some resemblance to bankruptcy court proceedings.
Companies and industries over-exposed to this desperation cycle will struggle to control their margins and competitive pricing. Be careful of locking into multi-year contracts with consumption based pricing.
Hybrid cloud takes on new relevance
To manage your exposure to the economics of compute, do a careful analysis of costs based on the size and type of your compute workloads. The "everything to cloud" mantra may not make sense for some of your compute workloads.
Your goal should be to gain a clear understanding of:
- What workloads are a good match for smaller LLMs that you run on your own hardware?
- What workloads are complex enough to warrant exploratory subscriptions to high cost frontier models?
- If you have high volume high complexity workloads, are they generating sufficient revenue to pay for inflated compute costs while also delivering acceptable margins?
Know the point where it makes more sense to capitalize hardware vs carry ongoing cloud costs.
Bottom line: If you purchased hardware between the pandemic price spike and the AI price spike (roughly 2022-2025 Q1), you have a structural cost advantage others don't.
Raise the Cost IQ of your team
Forward looking orgs are encouraging their technical teams to get familiar with what LLMs can be effectively run from owned hardware at different levels of scale:
- What can we run off a laptop?
- What can we run on low end servers?
- What can we run on high end servers?
- What absolutely requires and justifies the cost of OpenAI, Anthropic and the like?
This means encouraging teams to experiment with smaller LLMs to see what kind of performance they can squeeze out of non-cloud configurations.
For routine coding tasks—syntax completions, formatting suggestions, or code snippets—an 8-billion-parameter model can handle common patterns and syntax efficiently. Programming and scripting languages have well documented, finite rules that smaller models can manage adequately.
If developers in your org need complex reasoning—like understanding project-wide architecture, cross-file logic, or nuanced refactoring—then larger models can offer deeper insights. But if the tasks are mostly “fill in this function” or “suggest this loop,” a local model could be a great cost-saving baseline. Start local—and if you hit limitations, scale up selectively.
Takeaways
The pervasive thought pattern of 2024-2025 - jump in with both feet, costs don't matter - hasn't aged well. It's time for teams to build their internal expertise in how to match compute workloads against the most cost effective compute - vs blindly subscribing to whatever the cloud vendors are offering.
Decisions about how to purchase compute - when local is enough and when to scale up - need to be informed by hands on experimentation. This will allow you to approach AI investments armed with clear comparisons, not guesswork. It will also boost your team's resilience and flexibility, so you can adapt as workloads - and their economics - continue to evolve.
Have a great weekend, and a wonderful week ahead.
Ralph
Opinions expressed are those of the individuals and do not reflect the official positions of companies or organizations those individuals may be affiliated with. Not financial, investment or legal advice, and no offers for securities or investment opportunities are intended. Mentions should not be construed as endorsements. Authors or guests may hold assets discussed or may have interests in companies mentioned.
Member discussion